
June 2026
Most enterprise data lives in more than one place. One team standardizes on AWS, another on GCP; an acquisition arrives with its own lakehouse; each platform team stands up its own Iceberg REST Catalog. Every estate at scale spreads out like this; it is the normal condition, not an exception to design away.
Two approaches are usually on offer, and both exact a heavy price. One is to attempt consolidation: migrate everything into a single central catalog, a project measured in quarters and resisted at every step by the teams it strips of autonomy and control over their own data. The other is to leave each system to itself and stitch access together by hand, with per-system credentials and custom integration, which fragments governance instead of unifying it: access control gets reimplemented a dozen times, long-lived credentials sprawl across clouds, and no single audit trail can say which user or agent reached what.
Gravitino takes a third path: govern data where it lives, across whatever systems it already runs in, without copying it and without taking ownership away from the teams that hold it. That is what Apache Gravitino 1.3 delivers. Two headline capabilities lead the release, and a broad set of supporting features rounds it out.
The two highlights:
- Multi-cloud within a single catalog. One Iceberg REST Catalog serves S3, GCS, and ADLS at once, dispatching storage by URI scheme and vending short-lived, scoped credentials per request. What used to require a federation layer is now a single view.
- Federated IRC. A Gravitino IRC federates other Iceberg REST Catalogs without copying metadata. The owning catalog authorizes the real user, vends its own credentials, and keeps its own audit record. Governance stays at the source.
Also in 1.3: a general-availability Iceberg metadata cache, a new AWS Glue catalog, a built-in identity provider with compliance-grade audit, governed agentic access over MCP, highly available IRC deployments, and unified view management across catalogs and engines.
Highlight: One Catalog, Every Cloud
Multi-cloud is usually solved at the wrong layer. Either every cloud receives its own catalog, fragmenting the estate, or engines are configured with per-bucket credentials, leaving security teams to manage a sprawl of long-lived keys.
Gravitino 1.3 introduces multi-backend dispatch in the Iceberg REST Catalog. A new MultiSchemeFileIO routes storage operations by URI scheme, allowing a single catalog to simultaneously serve a default warehouse alongside alternate backends on other clouds while remaining fully IRC-compliant. Engines require no changes, and connectors require no forks; the difference between clouds is reduced to a LOCATION clause:
CREATE TABLE catalog.ns.t1 (id BIGINT, ...);
CREATE TABLE catalog.ns.t2 (id BIGINT, ...) LOCATION 's3://bucket/t2/';
CREATE TABLE catalog.ns.t3 (id BIGINT, ...) LOCATION 'gs://bucket/t3/';
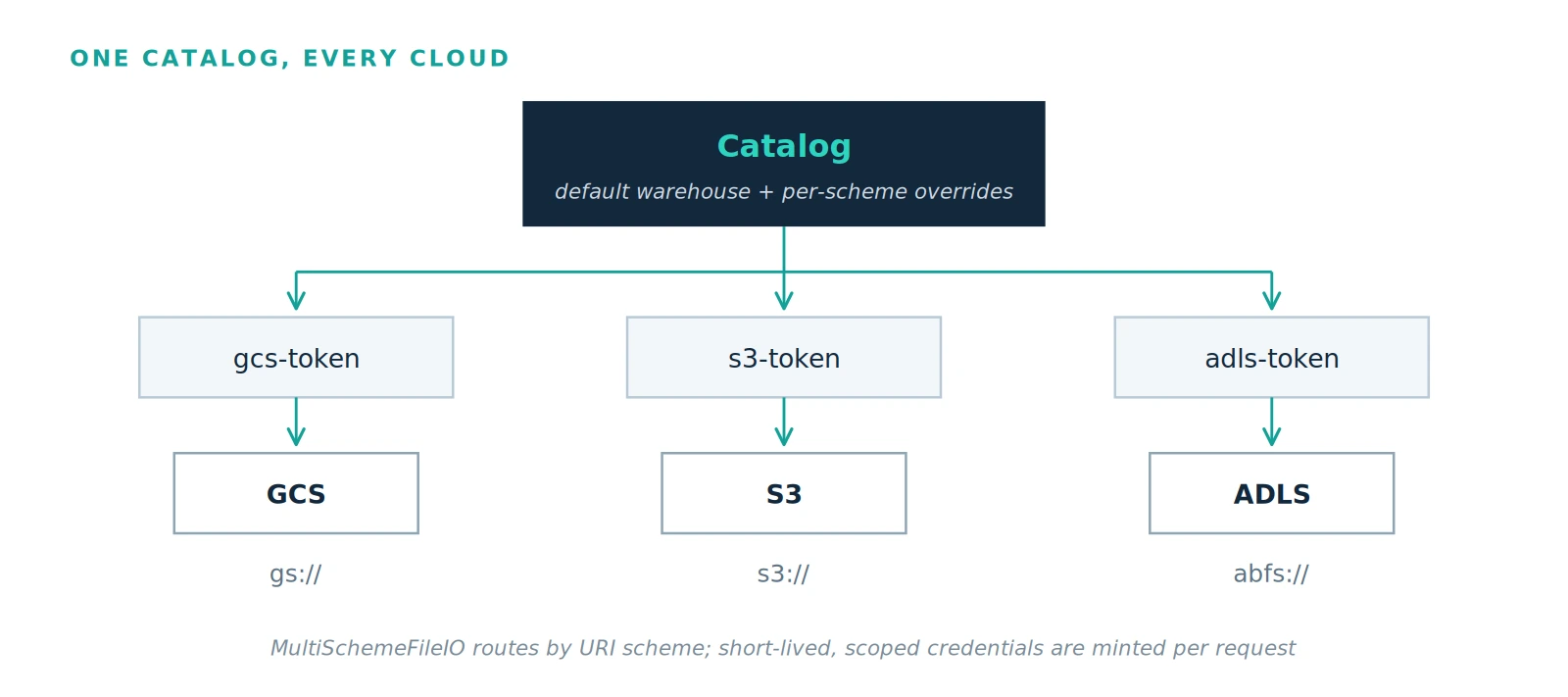
On every loadTable, Gravitino reads the table location, extracts the URI scheme, and routes to the matching credential provider. Exactly one provider claims each scheme, and the tokens it vends are path-scoped and short-lived: an STS AssumeRole token for S3, a downscoped OAuth token for GCS, a user-delegation SAS for ADLS. Engines never handle long-lived keys, and the caller's JWT identity flows from the engine through Gravitino to the object-store credential, so authorization is evaluated against the user making the request rather than a shared service account.
The dispatch model turns a namespace into a logical domain rather than a storage concept. A business unit can store each dataset by performance, cost, and security fit, group data by natural business relationships rather than physical boundaries, and preserve team ownership, all while a single Gravitino grant controls access to the domain. A view that joins a table on S3 with a table on GCS returns one result, drawn from two clouds.
Two further additions in 1.3 make the model production-grade. Vended credentials now refresh across S3, GCS, OSS, and ADLS, allowing long-running engine sessions to remain authenticated through token expiry rather than failing partway through a job. The client io-impl is now inferred from the table location, so clients select the correct storage implementation per scheme without per-table configuration.
The result is one catalog name, one governance model, and standard SQL across every cloud the estate actually spans.
Highlight: Federated IRC, Governed at the Source
The same problem recurs at a deeper level: not only is storage plural, the catalogs themselves are. Different platforms, clouds, and organizations each run their own Iceberg REST Catalog, with their own IAM, RBAC, and audit log. The consolidation playbook calls for merging them. The teams that own those catalogs generally decline, and for good reason: merging means surrendering control over access decisions, credential issuance, and auditing.
Gravitino 1.3 adds an Iceberg REST Catalog backend, enabling a Gravitino IRC to federate natively with other IRC services. The design rests on three principles:
Visibility, not replication. A remote IRC is registered by name and URI. No metadata is copied, so there is no second source of truth and no replication lag; the federated view reflects exactly what the remote catalog reports.
Ownership stays local. The local IRC forwards the caller's identity and makes no decisions of its own. The owning IRC authorizes the request against its own policies, vends its own short-lived credentials, and writes its own audit log. The data owner's controls are never delegated, re-implemented, or approximated.
Federation works across boundaries. Because nothing is shared except the request's shape, federation crosses network and cloud provider boundaries without a shared trust infrastructure. An on-premises deployment can federate a catalog running in GCP, and neither side relinquishes control to do so.
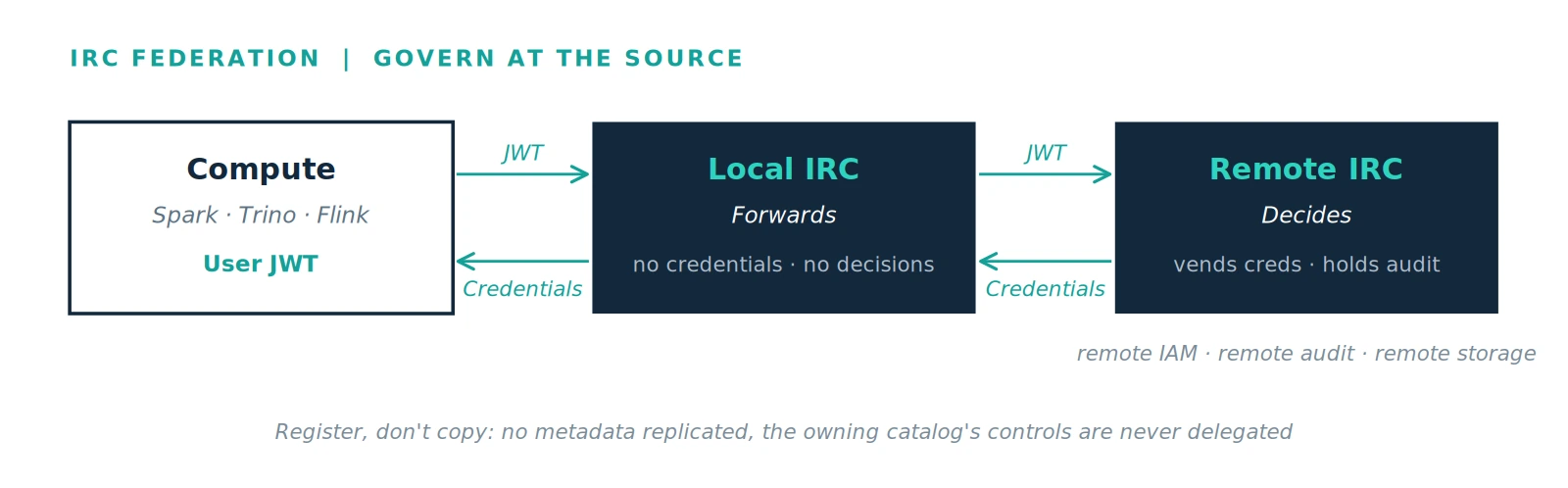
The mechanism that makes this work is bearer-token forwarding. On every call to a remote catalog, the local IRC re-attaches the user's own bearer token, unchanged, and the owning catalog validates it and authorizes the real caller. There is no service account, no token exchange, and no central store of credentials to steal. When a token needs refreshing, the local IRC re-forwards to the remote on the user's behalf. Because the owning catalog sees the actual person on every request, the question of who accessed what is answerable exactly where the data lives.
Federation therefore behaves like a data mesh built from existing catalogs. Each owner keeps its own authorization, credentials, and audit as a structural property rather than a privilege you grant. A catalog can be shared across business units, partners, or an acquired company without exchanging credentials or merging governance.
Readers of our 1.2 release post will recognize the philosophy. We argued then for the INVOKER model in view authorization: permissions should be evaluated against the user actually making the request, rather than inherited from whoever created an intermediary object. Federation applies the same principle at the estate scale. Governance authority belongs where the data lives, and the architecture should make that arrangement the path of least resistance rather than a discipline teams must maintain by hand.
The Iceberg Metadata Cache Goes GA: Faster Reads, Correctness Preserved
Under query planning, BI refreshes, and high concurrency, engines load the same unchanged tables many times. Caching that metadata in an Iceberg REST Catalog appears straightforward until the failure modes are considered. Serve a stale entry, and an engine plans against a commit that no longer exists. Skip the access check on a cache hit, and the cache becomes an authorization bypass. A naive implementation is a correctness defect waiting to be exposed by production traffic.
With 1.3, Gravitino's Iceberg table metadata cache graduates to general availability and is enabled by default, with increased default capacity. The design principle is that the fast path and the safe path are the same:
- In-memory. Parsed metadata is served from the IRC process with no extra hop and no object-store read.
- Location-validated. Before serving a cached entry, the server validates the entry's pointer against the backend. A stale commit is never served; a miss or an invalidated entry falls through to the backend and refreshes the cache.
- Authorization always enforced. Every request continues to carry identity, object, and operation through the access check. A cache hit accelerates metadata retrieval; it never bypasses a privilege evaluation.
- Bounded. Capacity and TTL-based expiry keep server memory predictable, and the implementation is pluggable through the
TableMetadataCacheinterface for deployments with different needs. - ETag-aware. An unchanged table returns Not Modified, so the client skips the transfer, not just the read.
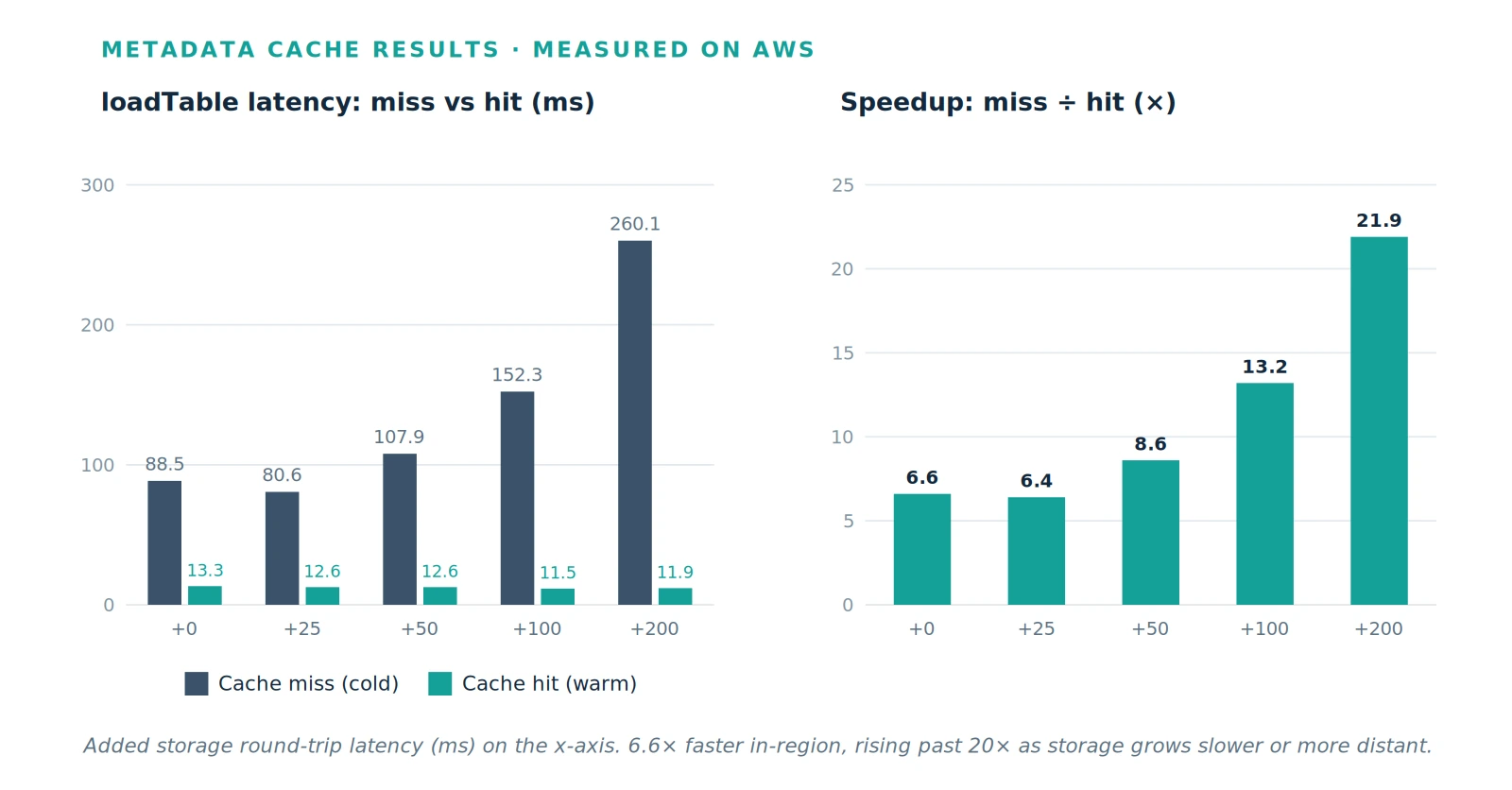
Measured on AWS, a warm cache loads tables 6.6x faster than a cold one in-region, and the benefit grows as storage gets slower or more distant, rising past 20x at the high end. The advantage scales with storage latency precisely because the cache removes the object-store round-trip that dominates cold loads: when that round-trip is cheap the saving is modest, and when it is expensive the saving is large.
AWS Glue, Governed in Place
For a large share of AWS customers, the question is not whether they have a Glue Data Catalog but how many. Glue arrives with the account, organically accumulates tables, and frequently ends up holding a meaningful fraction of the estate outside whatever governance layer the platform team has built.
Gravitino 1.3 ships a new AWS Glue catalog that brings those estates under unified governance without migration. It covers full schema and table CRUD with a complete type map including nested struct, array, and map types. Hive-format tables with identity partitions and native Iceberg tables sit side by side, each surfaced with its format intact, and Iceberg works two ways: through the AWS Glue SDK, or through the Iceberg SDK that writes metadata.json and metadata_location so Trino reads it natively. The Spark connectors for 3.3, 3.4, and 3.5, along with Trino, route through Gravitino, so engines query Glue-governed tables with the same fully qualified names, roles, privileges, and audit trail as every other asset in the metalake.
The release also adds a Hologres JDBC catalog, extending governance to Alibaba Cloud's real-time warehouse alongside the existing relational catalogs.
Enterprise Identity and Access, Out of the Box
Access control is only as deployable as the identity infrastructure behind it. Until now, Gravitino required an external identity provider, an appropriate requirement for large enterprises, but a genuine barrier for everyone else, including the proof of concept that determines whether the large enterprise deployment ever happens.
Gravitino 1.3 adds a built-in identity provider: users and groups stored in Gravitino with no external directory to wire up, password authentication with hashed credentials over HTTP Basic, full REST management for creating users and groups and changing passwords, and the same RBAC every other principal receives. Local users get roles, groups, and privileges like anyone else. The capability is built for simpler, single-Gravitino deployments; federated IRC and SSO continue to use OAuth2 or an existing IdP. It also gives enterprise operations teams a long-requested capability: local break-glass users. When the external IdP is unreachable, misconfigured, or itself the subject of an incident, designated local accounts preserve administrative access, scoped for emergencies rather than daily use and audited like any other principal.
Access control matures alongside identity:
- Group-aware ownership and role inheritance. A group can now own metadata objects, and a role assigned to a group is held by every member. Join the group to gain the role, leave it to lose the role, with no new grant per person, so access follows the org chart and ownership survives team changes.
- Scoped delegated administration. Scoped
MANAGE_GRANTSallows a platform team to delegate a bounded set of privileges without conferring global administrative rights. A grant can allow a whole catalog while a deny at any scope overrides it, so one function can be blocked inside an otherwise permitted catalog. - Function authorization. Gravitino 1.2 made UDFs first-class, governed catalog objects. 1.3 completes the model with a
FUNCTIONmetadata object type andREGISTER,EXECUTE, andMODIFYprivileges at catalog, schema, or function scope, with grants inheriting downward. The logic that transforms the data is now access-controlled in the same manner as the data itself.
Broadening Governance: Agents, Formats, and AI Data
Beyond the headline work, 1.3 widens what Gravitino governs and who it governs for:
- Governed agentic access over MCP. An agent or LLM calls Gravitino through its MCP server carrying the user's own token. The MCP server forwards the request's
Authorizationheader to Gravitino unchanged, preserving the caller's OAuth2 Bearer credential, and Gravitino authorizes the request against the same RBAC it applies to any caller and audits every call under the real user, never a shared service account. Agentic access becomes a governed path rather than a hole cut around governance to make automation convenient. - Wider view coverage. View support now spans Hive and Apache Paimon alongside Iceberg, under one API and a multi-dialect definition that holds several SQL dialects for a single view. Iceberg and Paimon store the view in their own native format while Gravitino enforces access control and audit on every use of it; Hive keeps the view in its metastore with Gravitino resolving the engine's dialect. A JDBC view model is coming next. Every view is evaluated under the INVOKER model introduced in 1.2, against the privileges of the user issuing the query.
- AI and multimodal data via Lance. The Lance integration moves to lance-core 6.0.0 and lance-namespace 0.7.5, with reliability fixes to describe-table materialization state, Web UI column population for engine-created tables, and the purge path for external tables, plus a smaller runtime footprint. Vector and feature data sits under the same catalog, access controls, and audit trail as the rest of the lakehouse.
Production Operations
A set of operational and reliability improvements makes the Iceberg REST Catalog ready to run, and prove, in production:
- Highly available IRC. The IRC runs as a fleet behind a load balancer, with state in a shared PostgreSQL store and shared object storage rather than on any node. Nodes can be added or removed without downtime, and in 1.3 they stay consistent across the fleet through a redesigned cache built on optimistic concurrency control.
- Compliance-grade audit. Events are emitted as structured JSON for Splunk, Datadog, or Elastic, with millisecond ISO 8601 timestamps, every action attributed to the real user, the real client IP captured behind load balancers, secrets scrubbed at the source, and failures recorded alongside successes. Logs rotate and retain on size and time.
- Freshness-aware loading. ETag support ensures that metadata for unchanged tables is not re-transferred.
- Health endpoints. Liveness, readiness, and aggregate health checks are available on both the Gravitino and IRC servers.
- Apache Iceberg 1.11.0. The server side moves to the latest stable Iceberg release.
Datastrato Enterprise 1.3
Everything described here ships in the open Apache release, free to run in production with no asterisk. Datastrato Enterprise 1.3, built on the same Apache Gravitino 1.3, is for organizations that need a vendor standing behind the deployment: a support relationship with real accountability, packaging and a security posture their review boards will accept, operational tooling for running it at scale, and the assurances that turn an open-source project into something a business can commit to. If you are running Gravitino as critical infrastructure, Enterprise is the path to running it with a partner rather than alone. A dedicated announcement with full details is coming soon.
Get Started
Apache Gravitino 1.3.0 is available now.
- Documentation: gravitino.apache.org
- GitHub: github.com/apache/gravitino
- Community: Join the conversation on the Apache Gravitino mailing list and Slack
Thanks to everyone who contributed to the 1.3.0 release: code, reviews, testing, issue triage, design, and feedback. The full contributor list is in the release notes.
Apache Gravitino™ and the Gravitino logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. The use of these marks implies no endorsement by The Apache Software Foundation.