

Data silos - the eternal problem around data
Data silos have long been a persistent issue in the world of data management. They create barriers and inefficiencies by separating data into isolated systems, making it difficult to access and analyze information holistically.
A typical data platform architecture combines several data stacks to meet different needs.
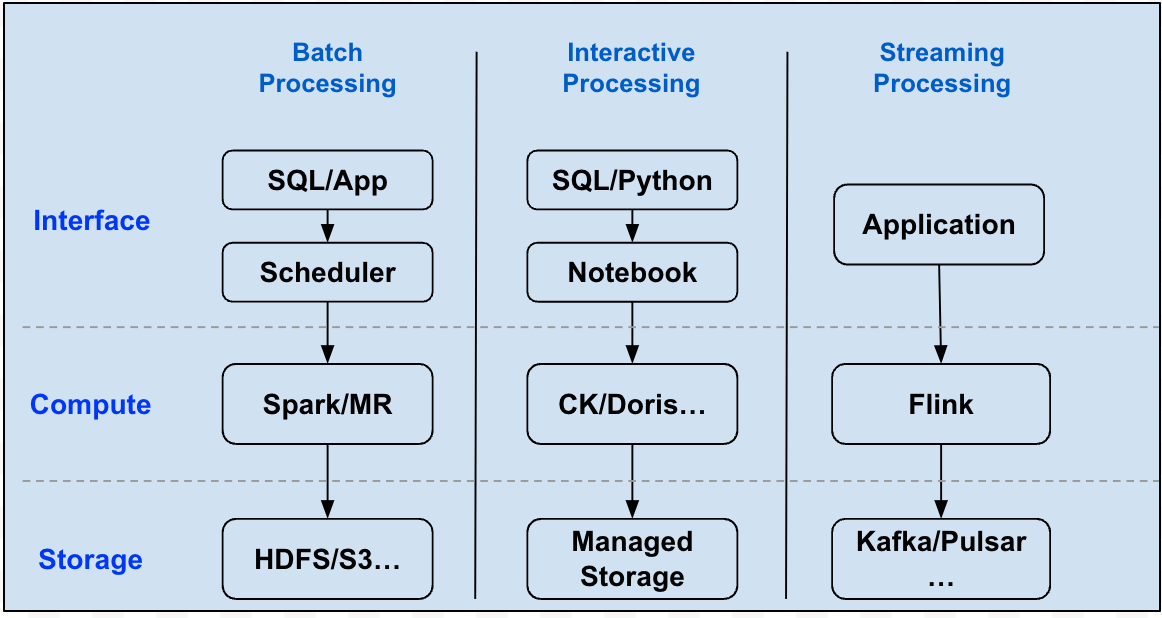
This architecture inevitably introduces the data silos between the stacks.
In response, Data Lakehouses tried to solve this problem by introducing new open table formats to provide the abilities of data warehouse with the flexibility of data lake storage, such as AWS S3, Azure ADLS, etc. This centralized solution enabled organizations to break down data silos and achieve a comprehensive view of their data assets while retaining scalability.
But still, it cannot meet the requirements of modern data analytics:
- The performance of the open table format cannot compete with some specialized data storage or formats.
- The challenge of a universal format to meet different data and AI scenarios is not trivial.
Cloud exacerbates the data silos
Currently, lots of companies and organizations introduce multi-regional or multi-cloud deployment for different reasons.
With the introduction of multi-regional or multi-cloud deployment, the problem of data silos becomes even more pronounced. It becomes challenging to maintain a unified view of the data across different regions or cloud providers.
From data analytics platform to data intelligence platform
In recent years, there has been a shift from traditional data analytics platforms to more advanced data intelligence platforms. These new platforms not only analyze data but also provide insights and recommendations for decision-making.
The shifting from a data analytics platform to a data intelligence platform reflects the increasing demands of metadata to train, prompt, and understand the organization.
Why unified metadata lake
- With the increasing complexities of modern data architecture, plus the trends of moving towards multi-regional or multi-cloud deployments, the centralized data lake or data lakehouse house solution becomes quite a challenge.
- With the increasing need to shift to a data intelligence platform, the importance of complete, high-quality metadata becomes quite important.
So, instead of centralizing all the data into ONE data lake to achieve SSOT (Single Source Of Truth), we propose a new architecture called metadata lake to unify all the metadata across data stacks, regions, and clouds.
Gravitino - the unified metadata lake
Gravitino is a high-performance, geo-distributed, and federated metadata lake. It manages the metadata directly in different sources, types, and regions. It also provides users with unified metadata access for data and AI assets.
The goal of Gravitino is to provide the user with a unified data management and governance platform no matter where the data stored.
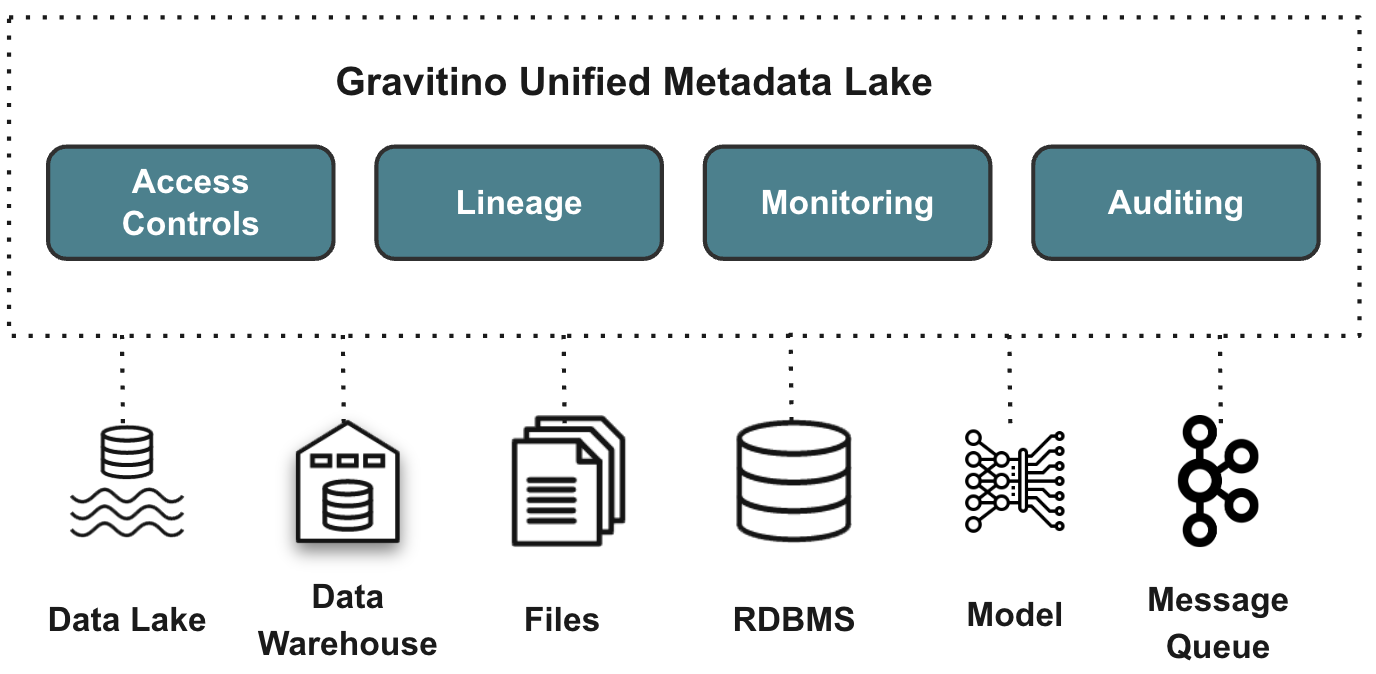
Gravitino aims to provide several key features:
- SSOT (Single Source of Truth) for multi-regional data with geo-distributed architecture support.
- Unified Data + AI asset management for both users and engines.
- Security in one place, centralizes the security for different sources.
- Built-in data management + data access management.
The architecture of Gravitino
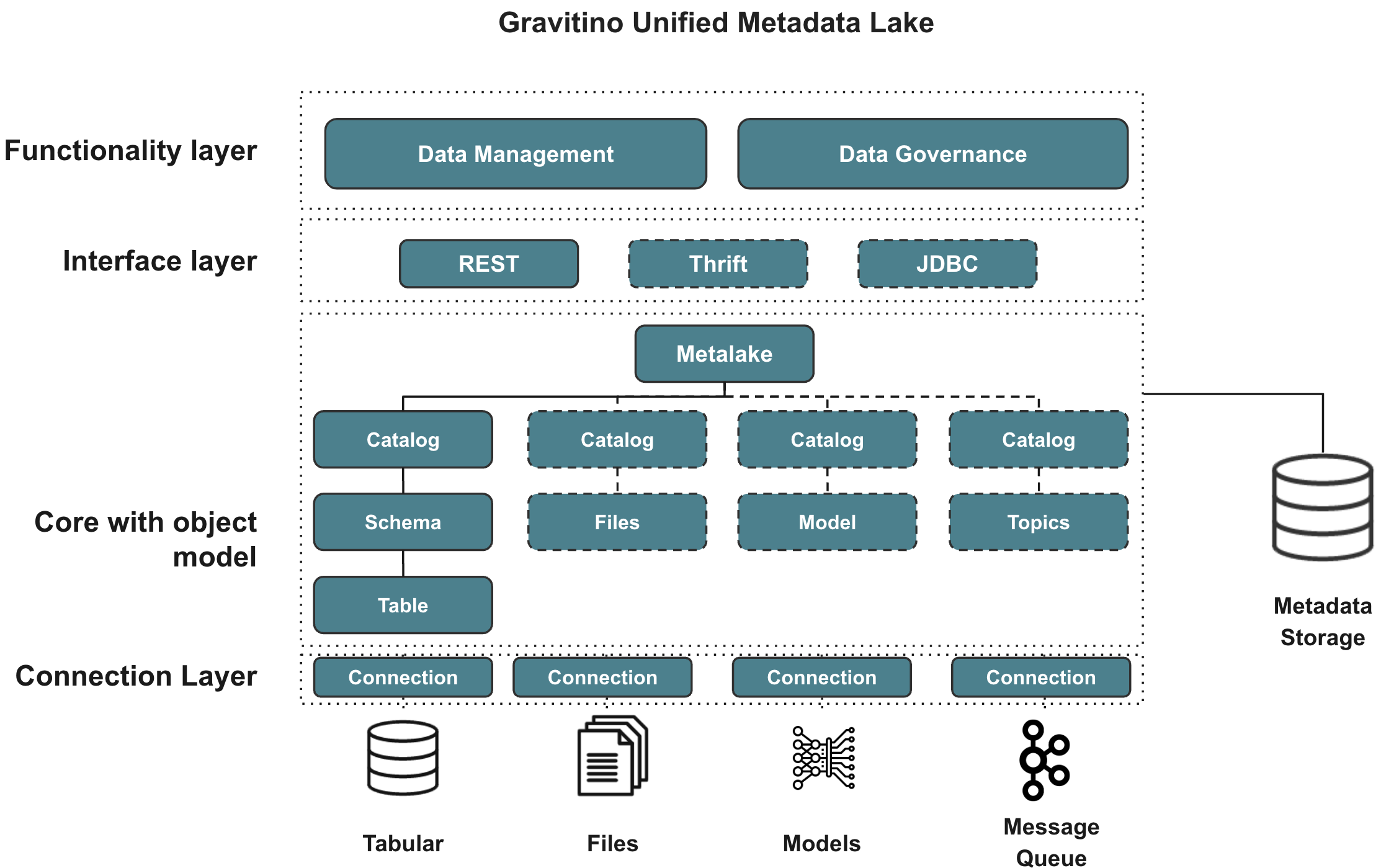
Gravitino model architecture
- Functionality Layer: Gravitino provides a set of APIs for users to manage and govern the metadata, including standard metadata creation, update, and delete operations. In the meantime, it also provides the ability to govern the metadata in a unified way, including access control, discovery, and others.
- Interface Layer: Gravitino provides standard REST APIs as the interface layer for users. Future support includes Thrift and JDBC interfaces.
- Core Object Model: Gravitino defines a generic metadata model to represent the metadata in different sources and types and manages them in a unified way.
- Connection Layer: In the connection layer, Gravitino provides a set of connectors to connect to different metadata sources, including Apache Hive, MySQL, PostgreSQL, and others. It also allows connecting and managing heterogeneous metadata other than Tabular data.
The key features of Gravitino
Unified metadata management and governance
Gravitino abstracts the unified metadata models and APIs for different kinds of metadata sources. For example, relational metadata models for tabular data, like Hive, MySQL, PostgreSQL, etc. File metadata model for all the unstructured data, like HDFS, S3, and others.
Besides the unified metadata models, Gravitino also provides a unified metadata governance layer to manage the metadata in a unified way, including access control, auditing, discovery, and others.
Direct metadata management
Unlike traditional metadata management systems, which need to collect the metadata actively or passively from underlying systems, Gravitino manages these systems directly. It provides a set of connectors to connect to different metadata sources, the changes in Gravitino will directly reflect in the underlying systems, and vice versa.
Geo-distribution support
Gravitino supports geo-distribution deployment, which means different instances of Gravitino can deploy in different regions or clouds, and they can connect to get the metadata from each other. With this, users can get a global view of metadata across the regions or clouds.
Multi-engine support
Gravitino supports different query engines to access the metadata. Currently, it supports Trino, users can use Trino to query the metadata and data without needing to change the existing SQL dialects.
In the meantime, other query engine support is on the roadmap, including Apache Spark, Apache Flink, and others.
Data + AI asset management
Gravitino supports managing traditional tabular data as well as new AI types of data, like features, vectors, models, etc. The combination of data and AI asset management gives the organization an integrated management of data everywhere.
There are still several features we don’t cover here, we will introduce them one by one in the follow-up blogs, please stay tuned.
The roadmap of Gravitino
The roadmap of Gravitino includes several key features and enhancements that are planned for future development. These include expanding support for additional query engines such as Apache Spark and Apache Flink, further improving the geo-distribution capabilities, and enhancing the unified metadata governance layer. Additionally, Gravitino aims to incorporate advanced features for data and AI asset management, ensuring that organizations can effectively leverage their data assets for AI model development and deployment. As Gravitino continues to evolve, it will remain focused on providing comprehensive solutions for unified metadata management and governance, catering to the diverse needs of modern data-driven enterprises.
Today, we open-sourced Gravitino, by open-sourcing the project, we welcome collaboration and innovation from all of you. This move will not only foster a vibrant developer community but also accelerate the evolution of Gravitino, ensuring that it remains at the forefront of the data and AI area.