





Apache Iceberg has gained popularity for its performance. However, it has some limitations due to client-side complexity. Gravitino, as a high-performance, geo-distributed, and federated metadata lake, is introduced to overcome the limitations. It manages the metadata directly in different sources, types, and regions. It also provides users with unified metadata access for data and AI assets. As one of its core features, gravitino provides a RESTful catalog service for accessing data from different databases, data warehouses, or even datalakes. With gravitino, Iceberg - including its pluggable catalog system and potential other lakehouses can be managed in a unified way and operated as a Single Source of Truth (SSOT).
Apache Iceberg™ and its pluggable catalog system
Project Iceberg is a high-performance format for huge analytic tables. It brings the reliability and simplicity of SQL tables to big data while making it possible for engines like Spark, Trino, Flink, etc. to safely work with the same tables, at the same time.
Iceberg introduces a pluggable catalog interface on the client side to manage table metadata for creating, altering, and dropping tables, allowing seamless integration with existing data systems. The plug-in implementations can be made to work with different data catalogs, such as Hive, Snowflake, Glue, etc.
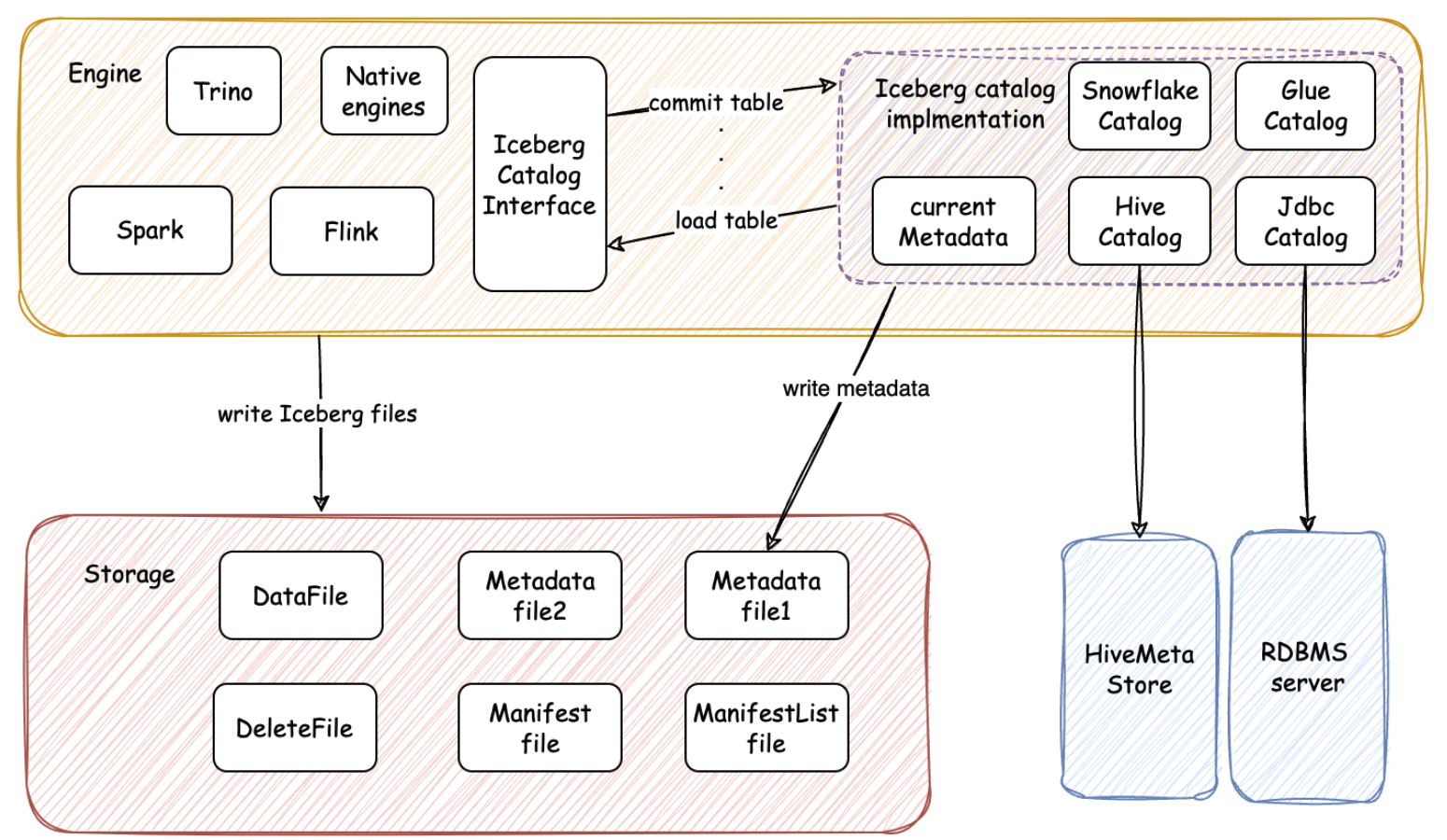
By abstracting the plug-in layer of the catalog interface, Iceberg effectively obscures the intricacies of metadata operations across various catalogs while managing table operations.
Why does the REST catalog service matter?
As mentioned above, the current catalog interface for Iceberg has client-side implementation which is easy to integrate with different query engines. Nevertheless, the client-side catalog plugin also faces certain limitations when transitioning to a production environment.
- Poor language and ecosystem compatibility
There are increasing requirements to analyze lakehouse data from native engines, like ClickHouse, Velox (written in C++), DataFusion (written in Rust), etc. Accessing Iceberg tables presents challenges, as all the aforementioned catalog implementations are developed in Java. The only solution is to refactor the Iceberg code into C++ or Rust, which introduces significant technical overhead and results in diminished tool compatibility.
- Performance limitations
The way the current client-based implementation works limits opportunities for performance enhancements, like caching table metadata in an unoptimized way. When cached table metadata is not able to be shared by other queries that are accessing the same table, a lot of redundancy occurs that slows down the fetching process.
- Complexity caused by guarantees of consistency from different catalogs
Consistency guarantees of the Iceberg table metadata are the core functions of the Iceberg Catalog. There are many other diverse implementations of this feature in different catalogs, such as the Hive Metastore lock in the Hive Catalog and the use of the atomic rename operations in the Hadoop Catalog. Maintaining consistency for different implementations is extremely challenging for developers who work on Iceberg tables.
- Limited capabilities, such as debugging, monitoring, and auditing
HiveCatalog uses thrift protocol, and JdbcCatalog uses JDBC protocol, which makes operations, such as debugging, monitoring, and auditing on catalog service, more challenging.
Due to the limitation above, there is a motivation for the REST catalog to move most of the above logic onto the server side, resulting in more lightweight clients. This is expected to have increased adoption and created a unified catalog to be used in different data engines and more scenarios with the following benefits:
- Good language and ecosystem compatibility
As mentioned above, native engines prefer to use client implementation of the same language. The more generic way is to implement a lightweight REST client to connect to a REST catalog service. This approach minimizes maintenance overhead for different clients implemented in different languages. This seamless integration makes it straightforward for other systems to collaborate with Iceberg tables. Notably, ongoing efforts aim to transfer more of the Iceberg client functionality into the Iceberg REST service, enhancing compatibility with various ecosystems.
- Performance Opportunities
By eliminating the constraints of client-side implementation, utilizing server-side caching becomes a viable method for improving performance. This is possible because the table meta request is centralized within the REST catalog service. The Iceberg community is actively pursuing various initiatives, such as avoiding commit conflicts and promoting the table scan API, all aimed at enhancing overall performance. The Iceberg REST service presents new opportunities for improving performance.
- Thin client layer with heavy-lifting work to the server side
With the REST catalog service, the client side can simply act as a wrapper of the REST client, allowing most of the heavy-lifting work to be moved to the server side. This makes the client upgrading process very simple, and the features customized on the server side will benefit all the clients without requiring individual client upgrades, resulting in significantly decreased maintenance efforts.
- Simplify guarantees of consistency for different catalogs
Compared to maintaining various consistency guarantee logics on the client side, the Iceberg client now only needs to send an HTTP request to the REST service. The REST catalog is responsible for ensuring the consistency of the metadata operations during concurrent requests to update iceberg tables.
- Ease of debugging, monitoring, and auditing
The HTTP protocol is human-readable, making it easy to add metrics and log HTTP requests, and facilitate easier debugging, monitoring, and auditing.
In response, the Iceberg 0.14.0 release ushered in the REST catalog, as outlined in the Iceberg REST API specification. However, this is just a partial implementation as only client API rather than server implementation. To implement the REST catalog service for Iceberg, we need to build a separate project or service, such as Gravitino.
Gravitino and its catalog system
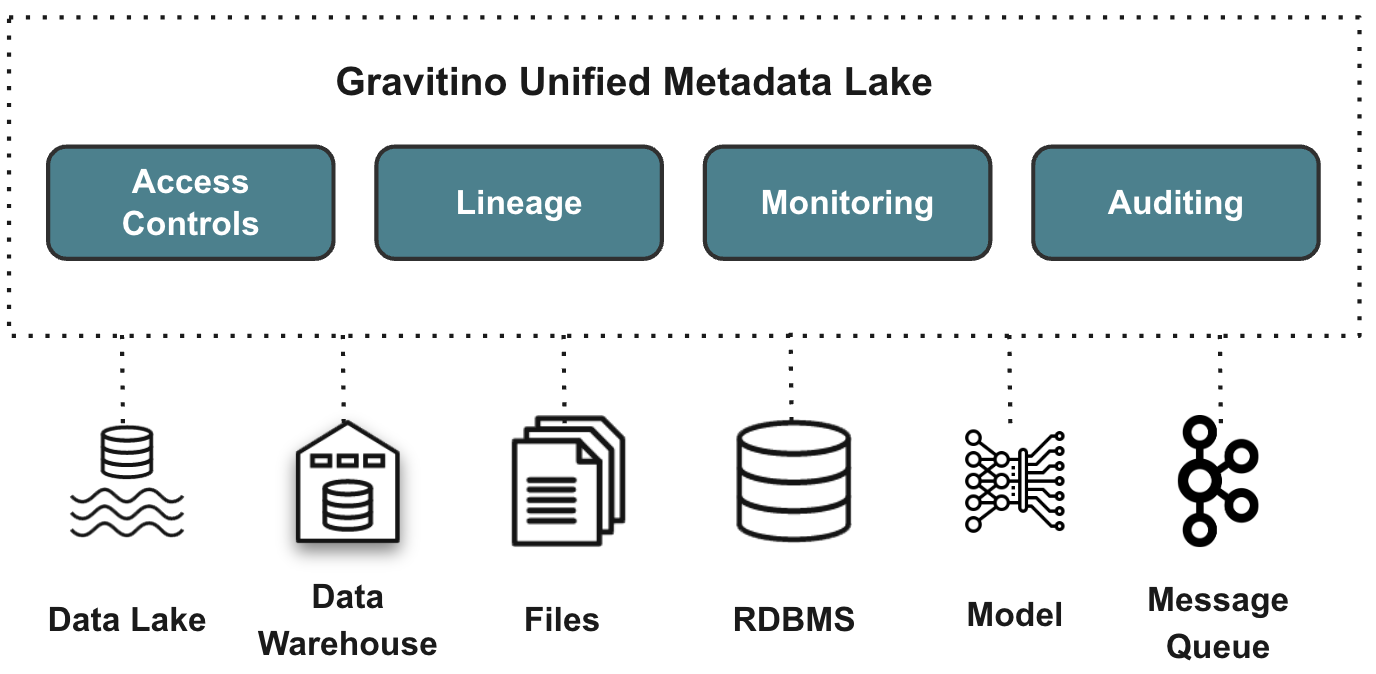
Gravitino is an open-source, high-performance, geo-distributed, and federated metadata lake. Built on top of Apache Iceberg, it manages the metadata directly in different sources, types, and regions at server side. It also provides users with unified metadata access for data and AI assets, as REST services.
Gravitino not only provides a unified interface to manage Iceberg metadata but also supports the Iceberg REST catalog interface to cooperate with existing data ecosystems. This makes Gravitino a data hub connecting all the data no matter what type and where it is located. Supporting the Iceberg REST catalog service matches perfectly with Gravitino’s goal.
How do we achieve it?
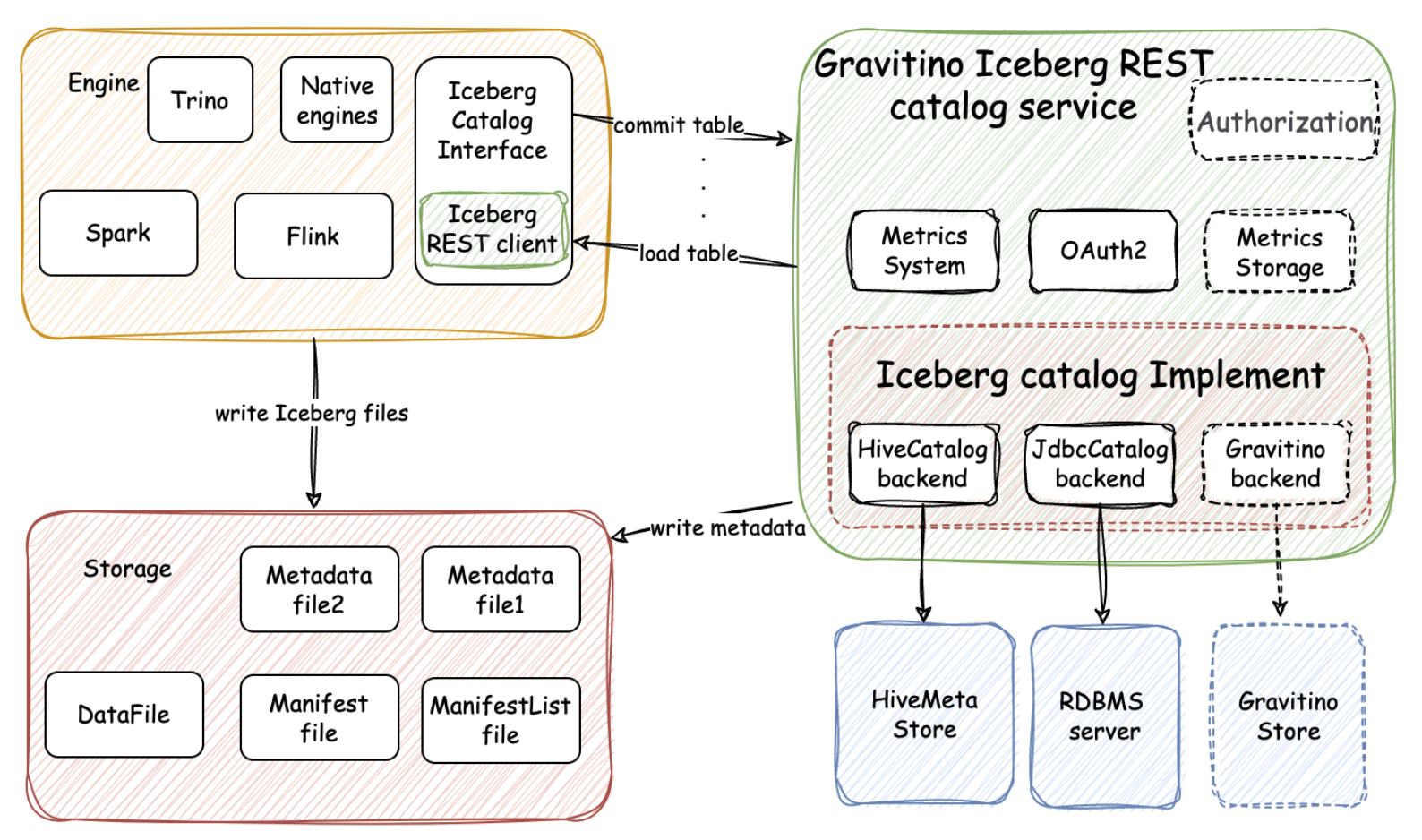
In Gravitino REST catalog service, the client side acts as a wrapper of the REST client, allowing most of the heavy-lifting work to be moved to the server side. As an initiative implementation, we integrate Hive catalog and JDBC catalog into Gravitino and wrap as server-side implementation for REST service. The Hive catalog has excellent compatibility with existing big data ecosystems, while the JDBC catalog has other benefits, such as a better locking mechanism, faster committing time, etc.
As a typical catalog service, Gravitino’s REST catalog covers all namespace and table operations, including creating, dropping, altering, and renaming tables. Besides these basic functionalities, some advanced features are also provided or planned:
-
Security Enhancement: We provide a unified security solution for REST catalog service, which includes OAuth2, Kerberos, LDAP support for authentication, IAM, Range support for authorization. And we continue to deliver security features as well as provide pluggable solutions for users to customize their solutions.
-
Ease of Maintenance: We offer a complete metrics system, auditing information, and loggings for users, users can easily integrate them into the in-house tools to make the maintenance easier.
-
Performance improvement: We provide a high-performance kv store as a built-in storage, with this we can further increase the performance of REST catalog service by storing the metadata in the kv store as well as a cache layer.
-
Pluggable Design: The core design principle of Gravitino is to make modules pluggable to satisfy different requirements, we provide pluggable authorization and authentication interface, metric store interface, and event listener, etc. We also provide some commonly used implementations, so users can use it out-of-box as well as customize it deeply.
To launch Gravitino service quickly, you can refer to the Gravitino Iceberg REST Service for more details.
So what’s next?
As a core component of Gravitino, the Iceberg REST Catalog service will continue its development and provide more features to enhance security, maintenance, and performance, aiming to be the production-ready open source implementation for the Iceberg REST catalog service. Besides the Iceberg catalog service, Gravitino will support other lakehouse formats, like: Hudi, Delta Lake, etc., to achieve the goal of a unified data catalog service for most enterprise data in data lakes.
As an open community, we welcome any ideas or questions only if you open an issue in the Gravitino GitHub repository for starting the discussion thread.
Acknowledgments
We received tons of valuable feedback from the community on the design of the Gravitino built-in Iceberg REST Catalog service. Special thanks to Yufei Gu(yufei_gu@apple.com) from Iceberg Community, Ashish Singh(ashishsingh@pinterest.com), Yongjun Zhang(yongjunzhang@pinterest.com) from Pinterest, Chao Shan(cshan@ebay.com) from eBay, and Daniel Dai (jidai@roku.com) from Roku - their expertise and advice have been instrumental in refining the design of the Gravitino REST catalog for Iceberg.