
Author: Xing Yong (Github Id: YxAc), Head of computing platform, Xiaomi Inc.

Xiaomi Inc. is a consumer electronics and smart manufacturing company with smartphones, smart hardware and electric cars connected by an IoT platform at its core. As of 2023, Xiaomi was ranked among the top 3 in the global smartphone market, according to Canalys, and listed as Fortune Global 500 for the 5th consecutive year.
The Xiaomi Cloud Computing Platform team is dedicated to providing reliable and secure data computing and processing capabilities for Xiaomi's business. We actively contribute to many open-source projects, covering storage, computing, resource scheduling, message queue, data lake, etc. By leveraging these advanced technologies, our team has achieved significant milestones, including winning the Xiaomi Million-dollar Technology Award Finalist.
This article focuses on the use of Gravitino in Xiaomi, providing solutions to future work plans and general guidance. There are, as follows, three key points and we look forward to growing our data-driven business with Gravitino.
-
Unifying our metadata
-
Integrating data and AI asset management
-
Unifying user permission management
1. Unify our metadata
With the introduction of multi-regional or multi-cloud deployment, the problem of data silos becomes even more pronounced. It becomes challenging to maintain a unified view of the data across different regions or cloud providers. This is really true for Xiaomi. Gravitino provides a solution to such challenges, and helps break down the data silos. It aims to solve such problems in data management, governance, and analysis in a multi-cloud architecture.
Gravitino's position in Xiaomi's data platform
Gravitino, highlighted in green and yellow in the diagram below, has the following features that we need :
-
Unified Metadata Lake: As a unified data catalog, it supports multiple data sources, computing engines, and data platforms for data development, management, and governance.
-
Real-time and Consistency: Real-time acquisition of metadata to ensure SSOT (Single Source of Truth).
-
Dynamic Registration: Supports adding/altering the data catalog on the fly, no need to restart the service, which makes maintenance and upgrades much easier than before.
-
Multi-Engines Support: not only Data engines, like: Trino, Apache Spark, Apache Flink (WIP), but also AI/ML frameworks, such as Tensorflow (WIP), PyTorch (WIP) and Ray (WIP).
-
Multi-Storage Support: Supports both Data and AI domain-specific storages, including HDFS/Hive, Iceberg, RDBMS, as well as NAS/CPFS, JuiceFS, etc.
-
Eco-friendly: Supports using external Apache Ranger for permission management, external event bus for audit and notification, and external SchemaRegistry for messaging catalog.
Feature is still in active development
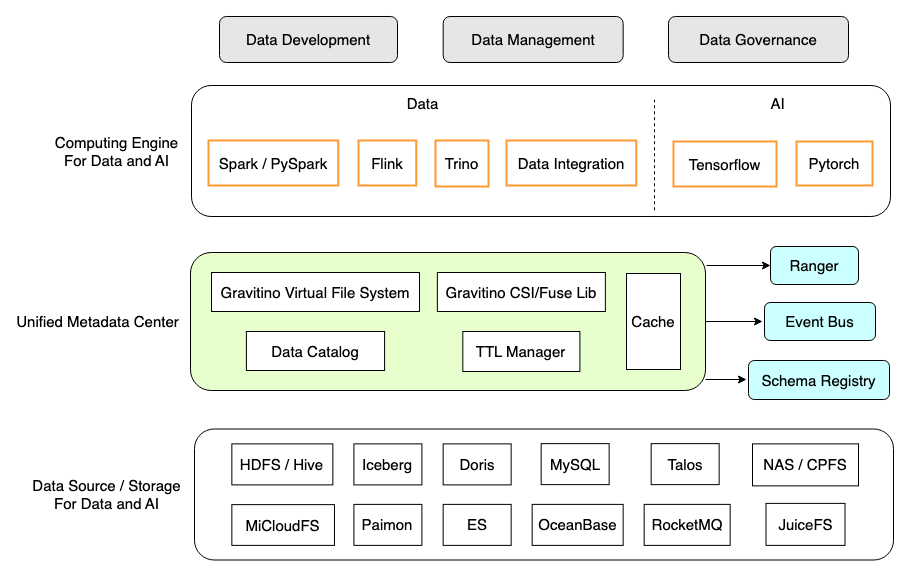
Unified metadata lake, unified management
As the type of data sources becomes more and more abundant, computing engines like Trino, Spark and Flink need to maintain a long list of the source catalogs for each of them. That introduces a lot of duplicated and complicated maintenance work.
To build fabric among multiple data sources and computing engines, it is often expected to manage all kinds of data catalogs in one place, and then use a unified service to expose those metadata. Gravitino is extremely useful in this context as it provides a unified metadata lake to standardize the data catalog operations, and unify all metadata management and governance.
User Story
Users can use a three-level coordinate: catalog.schema.entity to describe all the data, and used for data integration, federated queries, etc. What is exciting is that engines no longer need to maintain complex and tedious data catalogs, which simplifies the complexity of O(M*N) to O(M+N).
Note: M represents the number of engines, N represents the number of data sources.
Furthermore, we can use a simple and unified language to make data integration and federated queries:
- Apache Spark: Writing to Apache Doris from Apache Hive (with Gravitino Spark connector).
INSERT INTO doris_cluster_a.doris_db.doris_table
SELECT
goods_id,
goods_name,
price
FROM
hive_cluster_a.hive_db.hive_table
- Trino: Making a query between Hive and Apache Iceberg (with Gravitino Trino connector).
SELECT
*
FROM
hive_cluster_b.hive_db.hive_table a
JOIN
iceberg_cluster_b.iceberg_db.iceberg_table b
ON a.name = b.name
2. Integrate data and AI asset management
In the realm of big data, we have made significant progress through data lineage, access measurement, and life cycle management. However, in the domain of AI, non-tabular data has always been the most challenging aspect of data management and governance, encompassing HDFS files, NAS files, and other formats.
Challenges of AI asset management
In the realm of machine learning, the process of reading and writing files is very flexible. Users can use various formats, such as Thrift-Sequence, Thrift-Parquet, Parquet, TFRecord, JSON, text, and more. Additionally, they can leverage multiple programming languages, including Scala, SQL, Python, and others. To manage our AI assets, we need to take into account these diverse uses and ensure adaptability and compatibility.
Similar to tabular data management, non-tabular data also needs to adapt to a variety of engines and storages, including frameworks like PyTorch and TensorFlow, as well as various storage interfaces like FileSystem for file sets, FUSE for instance disk, CSI for container storage.
Non-tabular data management architecture
We aim to establish AI asset management capabilities by leveraging Gravitino, whose core technologies are outlined in the figure below.
-
Non-tabular data catalog management: Achieving the auditing for AI assets, and the assurance of the specification for file paths;
-
File interface support: Ensuring seamless compatibility with various file interfaces:
-
Hadoop File System: Achieving the compatibility with the Hadoop file system through GVFS (Gravitino Virtual File System).
-
CSI Driver: Facilitating the reading and writing of files within container storage.
-
FUSE Driver: Enabling the reading and writing of files directly on the physical machine disk.
-
-
AI asset lifecycle management: Implementing TTL (Time-To-Live) management for non-tabular data.
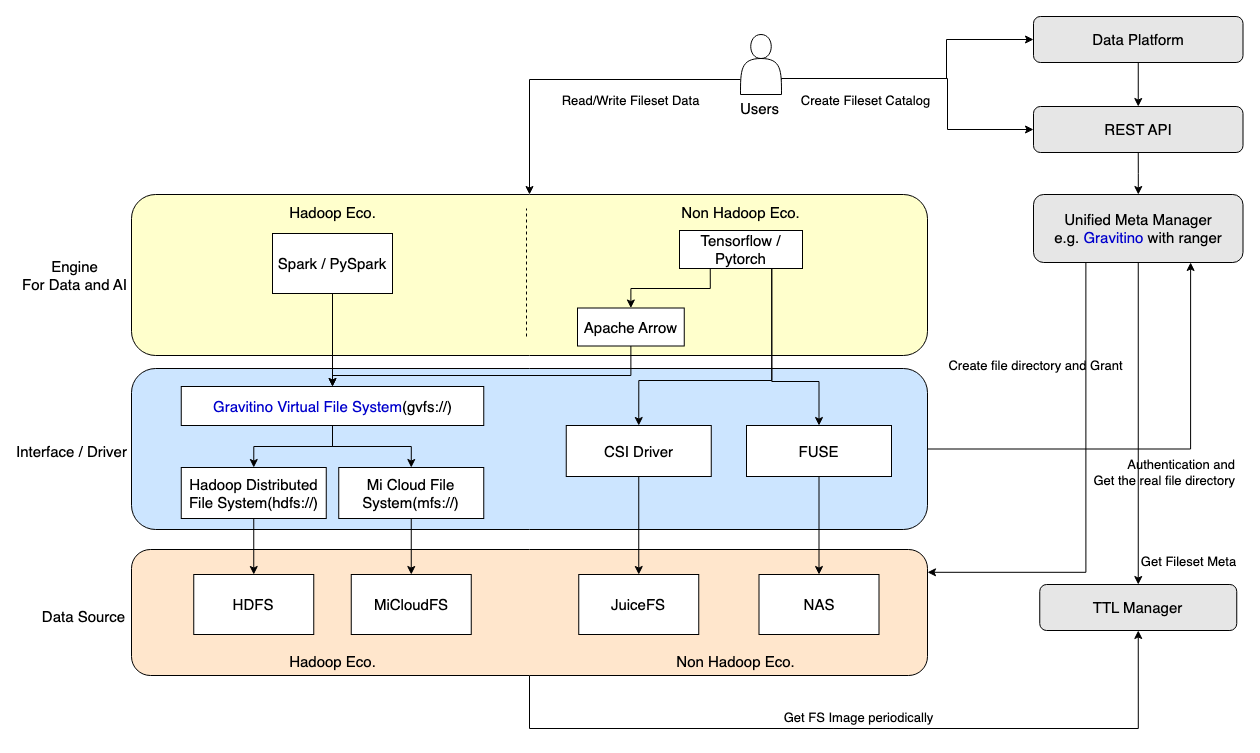
User story
We expect that the migration process for users from the original way to the new approach will be straightforward and seamless. In fact, the transition involves just two steps:
-
1)Create a fileset catalog with the storage location, and configure the TTL (Time-To-Live) on the Gravitino-based data platform.
-
2)Replace the original file path with a new way: gvfs://
To illustrate, let's consider the example of Spark reading HDFS files as follows.
// 1.Structured data - Parquet
val inputPath = "hdfs://cluster_a/database/table/date=20240309"
val df = spark.read.parquet(inputPath).select()...
val outputPath = "hdfs://cluster_a/database/table/date=20240309/hour=00"
df.write().format("parquet").mode(SaveMode.Overwrite).save(outputPath)
// 2.Semi-structured data - Json
inputPath = "hdfs://cluster_a/database/table/date=20240309_${date-7}/xxx.json"
val fileRDD = sc.read.json(inputPath)
// 3.Unstructured data - Text
val inputPath = "hdfs://cluster_a/database/table/date=20240309_12"
val fileRDD = sc.read.text(inputPath)
Leveraging Gravitino, we create a fileset called “myfileset” that is pointing to the origin HDFS, then we can replace the original hdfs://xxx with the new gvfs://fileset/xxx approach, offering users a seamless and intuitive way to upgrade. Users will no longer have to care about the real storage location.
// 1.Structured data - Parquet
val inputPath = "gvfs://fileset/myfileset/database/table/date=20240309"
val df = spark.read.parquet(inputPath).select()...
val outputPath = "gvfs://fileset/myfileset/database/table/date=20240309/hour=00"
df.write().format("parquet").mode(SaveMode.Overwrite).save(outputPath)
// 2.Semi-structured data - Json
inputPath = "gvfs://fileset/myfileset/database/table/date=20240309_${date-7}/xxx.json"
val fileRDD = sc.read.json(inputPath)
// 3.Unstructured data - Text
val inputPath = "gvfs://fileset/myfileset/database/table/date=20240309_12")
val fileRDD = sc.read.text(inputPath)
As previously mentioned, file reading and writing exhibit a lot of flexibility, it also adapts to diverse engines. Instead of enumerating individual examples, the overarching principle remains that users should be able to manage and govern non-tabular data with minimal modifications.
Many challenges within AI asset management require exploration and development work. It includes specifying the depth and date of file paths, facilitating data sharing, exploring non-tabular data reading and writing solutions based on the data lake like Iceberg. Those will be our focus in the near future.
3. Unify user permission management
Metadata and user permission information are so close to each other, and it is always a good idea to manage them together. The metadata service also needs to integrate user permission-related capabilities to authenticate resource operations. We expect to achieve this in our data platform by leveraging Gravitino.
Challenges of unified authentication across multi-system
In order to provide users with a seamless data development experience, the data platform often needs to be integrated with various storage and computation systems. However, such integrations often lead to the challenge of managing multiple systems and accounts.
Users need to authenticate themselves using different accounts in different systems like HDFS (Kerberos), Doris (User/Password), and Talos (AK/SK - Xiaomi IAM account). Such fragmented authentication and authorization processes significantly slow and can even block development.
To address this issue, a crucial step for a streamlined data development platform is to shield the complexity of different account systems and establish a unified authorization framework to increase the efficiency of data development.
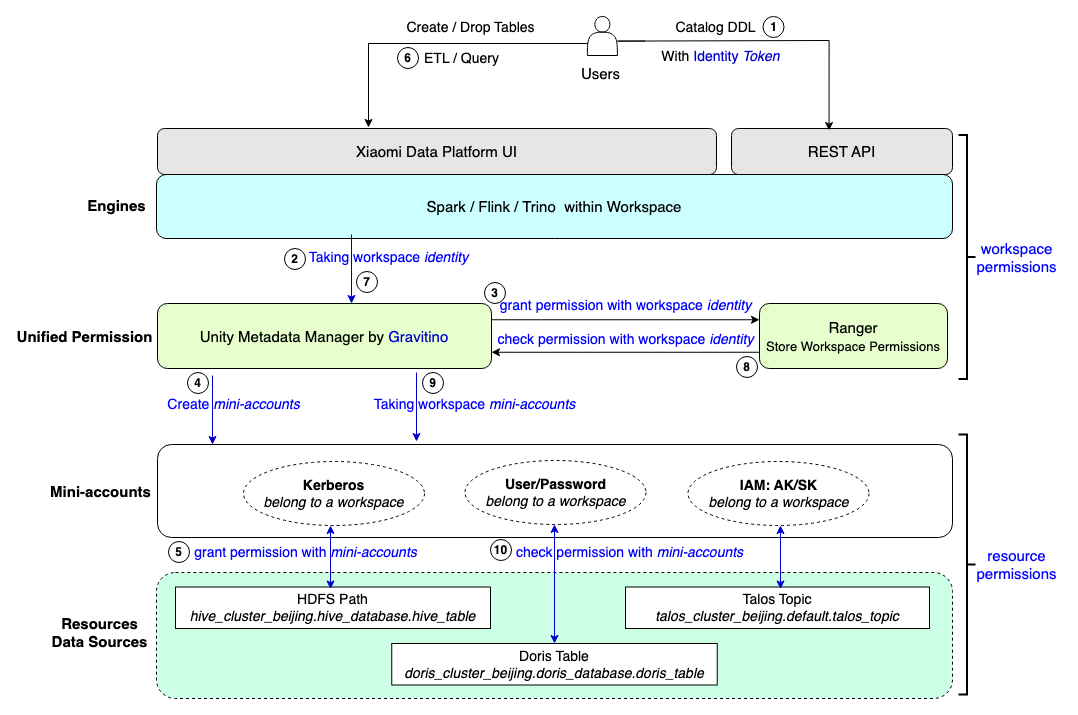
Unified user permissions based on workspace
Xiaomi's data platform is designed around the concept of Workspace and utilizes the RBAC (Role-Based Access Control) permission model. Gravitino allows us to generate what we call "mini-accounts" (actual resource accounts, such as HDFS-Kerberos) within the workspace, effectively shielding users from the complexities of Kerberos, User/Password, and IAM/AKSK accounts.
Here are the key components of this setup:
-
Workspace: Workspaces serve as the smallest operational unit within the data platform, containing all associated resources.
-
Role: Identities within the workspace, such as Admin, Developer, and Guest. Each role is granted different permissions for accessing workspace resources.
-
Resource: Resources within the workspace, such as catalog.database.table, are abstracted into three-level coordinates thanks to unified metadata.
-
Permission: Permissions determine the level of control granted to users for operating resources within the workspace, including admin, write, and read.
-
Token: A unique ID used to identify individuals within the workspace.
-
Authentication: API operations are authenticated using tokens, while IAM identities are carried through UI operations after login.
-
Authorization: Authorization is managed through Apache Ranger, granting the necessary permissions to authenticated workspace roles.
-
Mini-account: Each workspace has a dedicated set of proxy accounts to access the resources, such as HDFS (Kerberos) or Apache Doris (User/Password). When the engine accesses the underlying resources, it seamlessly utilizes the corresponding mini-account authentication for each resource. However, the entire process remains transparent to the user, who only needs to focus on managing workspace permissions (which are equivalent to resource permissions by leveraging Gravitino).
User story
The figure below shows a brief process for users to create and access resources on our data platform:
All users are only aware of the workspace identity and workspace permissions.
Upon creating a workspace, a suite of workspace proxy mini-accounts is automatically created. Whenever resources are created or imported within the workspace, the corresponding proxy mini-account is authorized with the necessary resource permissions.
When a user attempts to read or write to a resource, the system verifies their workspace permissions. If the workspace permission check is successful, the engine utilizes the mini-account to perform the desired read or write operation on the resource.
Summary
In this blog, we showcase three important scenarios at Xiaomi that we’re using Gravitino to accomplish - most of the critical work has been done, the rest are ongoing with good progress. We're confident in the successful landing of all above scenarios in Xiaomi to support our data-driven business in a better way, and we are glad to be part of the Gravitino community to co-create the potential de-facto standard of the unified metadata lake.